Update:
I’ve since cleaned up the code here and published it as a tiny library: pea on github
Aside: why cucumber doesn’t work as well as everyone thinks it should
I’ve used cucumber at work for a reasonably large project, and I wasn’t impressed. Having one canonical language for stories sounds great, until you have enough arguments about how things should be phrased that you eventually come to the realisation that BAs don’t want to write their specifications as tests, and you don’t write your tests as specifications.
This is a test style assertion step:
Then the total of the items should be 42
..and this is the same step in a requirements-style of language:
Then the total of the items should equal the sum of the number of items in each category
To a BA, the first example is a lie. The sum shouldn’t be 42, it should be the correct number! And to an automated program, the second statement is nigh on useless. Saying what something is supposed to be made from is just doing the same calculation twice - there’s nothing stopping you from doing it wrong both times! If you want to check that it’s getting the right answer, you need to tell it what the right answer is, not just tell it (again) how to make it.
So I’m not a huge fan of having cucumber scenarios be the single source of truth for requirements. If the programmers have their way it’s just a series of examples (also known as “tests”), and if the BAs have their way it’s just a series of feeble assertions that don’t necessarily check what they say they’re checking.
But it’s not all bad…
But on programmer-oriented projects, I can see them working quite well. For example, I’ve recently upgraded a large suite of specs to rspec 2, and made heavy use of the browsable cucumber scenarios on relishapp.com as actual, useful documentation.
So I decided to try cucumber on one of my own projects. Since I am obviously a python fiend outside of work, I wasn’t going to use cucumber. So out came the (very young) python port of cucumber, called lettuce (where did this salad theme even come from? o_O). I gave it a go, and of course it’s naturally a bit more awkward than ruby because python doesn’t have blocks. It’s also more than a little buggy, and lacking some useful features that cucumber has (which is to be expected of such a young project).
I started hacking on it to add or improve features, and then got sick of it. It really does seem a little ridiculous. We’re actually inventing a (trivial) language, and parsing it, and using little regex parsers in each of our steps, and mapping each of those regexes to little chunks of code. And all this makes it hard to find usages, hard to track duplication and dead code, and generally just awful to navigate and manage.
The punchline
So, you know what? I just transformed all my steps into valid python code instead. Each regex replaced with a function name, and each matching group an argument (python’s keyword-arguments help here). 65 lines of code later, I have a very similar result using plain-old python.
Here is a comparison. The old feature:
Feature: running indicate-task
Running a basic, blocking process that
consumes and produces output.
Scenario: running and cancelling a program
When I run indicate-task -- cat
And I enter "input"
And I press ctrl-c
And I wait for the task to complete
Then there should be a "cat" indicator
And it should have a menu description of "cat: running..."
And the output should be: input
And the error output should be empty
And the return code should not be 0
And it should display the task's output to the user
And it should notify the user of the task's completion
And the new, normal, actual-python-code-that-works-just-fine-with-ctags-and-isn’t-built-with-dirty-regexes version:
from makeshift_cucumber import *
from base_test import BaseTest
class TestRunning(BaseTest):
"""
Feature: Running a basic, blocking process that
consumes and produces output.
"""
def test_running_and_cancelling_a_program(self):
When.I_run_indicate_task('--', 'cat')
And.I_enter("input")
And.I_press_ctrl_c()
And.I_wait_for_the_task_to_complete()
Then.there_should_be_an_indicator_named("cat")
And.it_should_have_a_menu_description_of("cat: running...")
And.the_output_should_be('input')
And.the_error_output_should_be_empty()
And.the_return_code_should_not_be(0)
And.it_should_display_the_tasks_output_to_the_user()
And.it_should_notify_the_user_of_the_tasks_completion()
No, you probably wouldn’t be able to get a businessman to write a scenario. But has that ever actually worked with cucumber either? I find it doubtful. The results are just as readable, and insanely simpler in terms of the complexity of the testing infrastructure. Plus, it’s just a normal test, the functions are just normal functions, and the arguments are just normal arguments.
And if you don’t want to give that to a BA, just show them the test output instead:
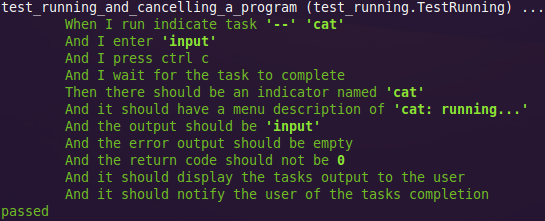
I’ll try to clean this up some time into a proper library & formatter sometime, because I think the mess of code you end up with cucumber is just too ridiculous for the benefits you get, and this sort of thing is much more developer-friendly while maintaining most of the readability benefits.
