
Running gnome-shell nested in a Xephyr window
TL;DR: install nix and Xephyr, then try this script.
I’ve worked on a GNOME Shell tiling window extension (shellshape) for 5 years now, since before the first release of gnome-shell. The shell itself is impressively extensible, and it’s pretty amazing that I can distribute a tiling window extension which as just a bunch of javascript. But the development process itself has always been awful:
- you have to restart your window manager all the time, which typically loses the sizing and workspace affinity of every window, leaving you with a tangled mess of windows
- if your extension doesn’t work then you have a broken shell
- it is painfully easy to cause a segfault (from JavaScript code :( )
- you’d better be editing your code in a
tmuxsession so you can fix it from a VTE - sometimes when restarting the shell, all your DBus-based integrations get messed up so you can’t change volume, use multimedia keys or shutdown
- testing against a new gnome-shell version basically means either upgrading your OS or trying to do a fresh install in a VM, which is a whole new layer of annoyance.
Maybe I’m spoiled from working on projects which are easily run in isolation - I bet kernel developers scoff at the above minor inconveniences. But it makes development annoying enough that I dread it, which means I’ll only fix bugs when they get more annoying than development itself.
All of which is to say that this is freakin’ awesome. As of a couple days ago I’ve been able to run the latest version of GNOME Shell (which isn’t packaged for my distro) in a regular window, completely disconnected from my real session, running the development version of shellshape.
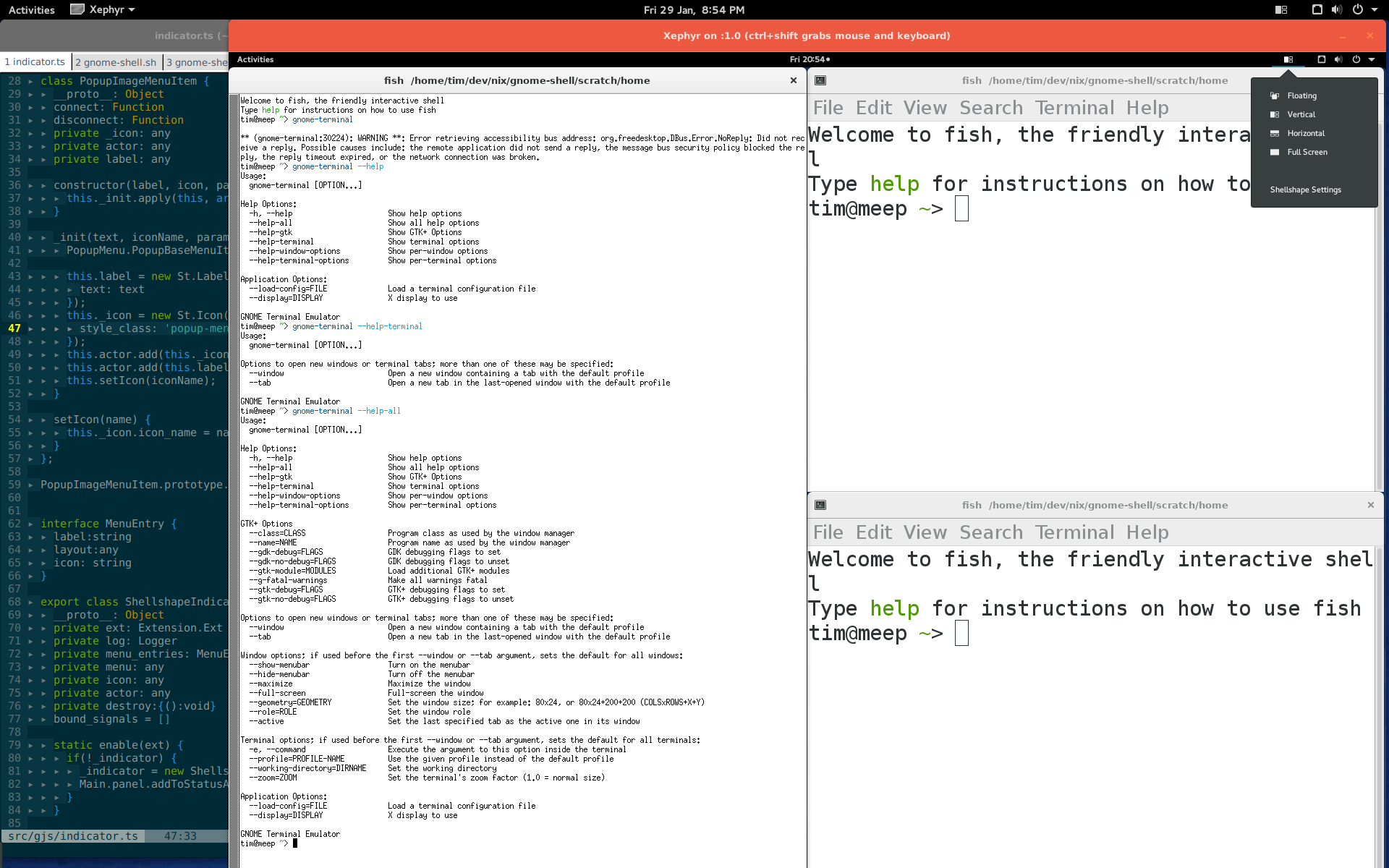{kind=link}
Big thanks go to whichever mysterious developers were responsible for fixing whatever gnome-shell / graphics / Xephyr issues have always prevented gnome-shell from running nested (it does now!), and to the nixpkgs folks maintaining the latest GNOME releases so that I can run new versions of GNOME without affecting the rest of my system.
Unfortunately I can’t guarantee it’ll work for you, since this stuff is heavily dependant on your graphics card and drivers, plus it only seems to work with my system version of Xephyr, not the nixpkgs one. But if this interests you, you should definitely give it a go. You’ll need nix and Xephyr. If you don’t want to use nix, you can probably extract what you need from the script to run your system version of gnome-shell in a Xephyr window.