or, “I’ve written a lot of software, and now I have regrets”
As time goes on, people write more software. Well, at least I do. And these days, it’s pretty easy to put up everything you’ve created on GitHub or somewhere similar.
But of course, not all software is created equal. That 100-line JS library I created in one day back in 2011 which has seen 3 commits since is probably not going to be as important to me as the primary build tool I use in my own projects, which has implementations in 2 languages, an extensive automated test suite, and which has steadily seen improvements and fixes over the past 2 years with more than 300 commits.
And people usually realise this. Based on project activity, date of recent commits, total number of commits, amount of documentation etc, you can often get a good idea of how healthy a project is. But is that enough?
I’ve had people report bugs in a project where my immediate thought has been “well, this is pretty old and I haven’t used it for years - I’m not surprised it doesn’t work”. Meanwhile I see comments about another project where someone will wonder whether it still works, since it hasn’t been updated in ages. To which my first thought is “of course it still works! It doesn’t need updating because nothing’s wrong with it”.
I’ll try and communicate this less bluntly, but clearly there’s information I (as the author) know that other’s can’t without asking me - from what others can see, the projects probably look just as healthy as each other.
Why are you publishing it if you don’t care about it?
I don’t want to maintain all the software I’ve ever written. I’ve written plenty of software for platforms or tools I no longer use. I’ve written software to scratch an itch I no longer have, or which I just can’t be bothered keeping up to date with breaking API changes.
I could just abruptly delete each project as I decide it’s not worth maintaining, but that’s both drastic and rude. Maybe it works fine, but I no longer use it. Maybe others still depend on it. Maybe someone else would like to step up and take it over, rather than see it die. Maybe it doesn’t work as-is, but people can learn from reading parts of the code that are still useful. I publish Open Source software because it might be useful to others - deleting it when I no longer have a use for it doesn’t fit with that spirit at all.
Stillmaintained
A while ago, there was this project called “stillmaintained”. It aimed to address the issue of communicating project health directly, by answering the simple question “Is this still maintained?”. Ironically (but perhaps inevitably), stillmaintained itself is no longer maintained, and even the domain registration has lapsed. But I think the problem is an important one.
My solution
I think the constraints are:
- It must be dirt easy for the author to manage. If it takes too much effort to update a project’s status, I’ll be too lazy to do it.
- The infrastructure itself must be super low maintenance. I don’t want to spend all my time maintaining the thing that tells you if my projects are maintainted!
So to solve the issue for my projects, I did the simplest dumbest thing:
- I created a few static images with Inkscape.
- In a folder that gets synced to this website, I made a bunch of files named
<projectname>.png, each of which is a symlink to a status (e.g. ../maintained.png, ../abandoned.png, etc).
- I embed that
<projectname>.png into the project’s README, documentation, etc.
- When I decide that a project’s status has changed, I modify the appropriate symlink.
Now the status for all my projects is managed in one directory, and I can generate a list of active projects with a simple python script. I don’t need to go and edit that project’s README, docs and packaging metadata - it all just points to the same place.
Here’s an example badge, for abandoned projects:
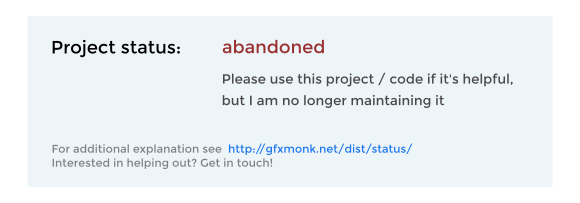
It’s not fancy. There are no RSS feeds or email notifications when the project status changes. Showing an image containing text is not very accessible, nor very flexible. But it’s the easiest way for me to tell visitors to my projects what my assessment of that project’s health is, which is something I’ve never had the ability to do very well before. And since it’s so low maintenance, I’m hopeful that I’ll actually keep these up to date in the future.
In open source software, the author is under no obligation to maintain or fix anything - it’s there, take it or leave it. That doesn’t tell the full story. I want people to use my code, so just ignoring users and possible contributors because I have no obligation to them is a great way to get a reputation as a terrible project maintainer. At the same time, there’s no way I can fully maintain all the software I’ve ever written, especially as time goes on and that set gets larger. So the best I can do is to try and honestly communicate my intent as part of each project’s public documentation.
